After Named Entity Recognition
指代消解主要有两个步骤。第一步是指代识别(mention detection),即找出句子中所有的指代,这一步相对简单;第二步才是进行真正的指代消解(coreference resolution),这一步比较困难。
指代(Mention)是指句子中的一个短语(span),它可以是代词、也可以是命名实体、还可以是名词短语。指代识别的方法有多种,比如词性标注(POS)、命名实体识别(NER)、语法分析器(parser)等。
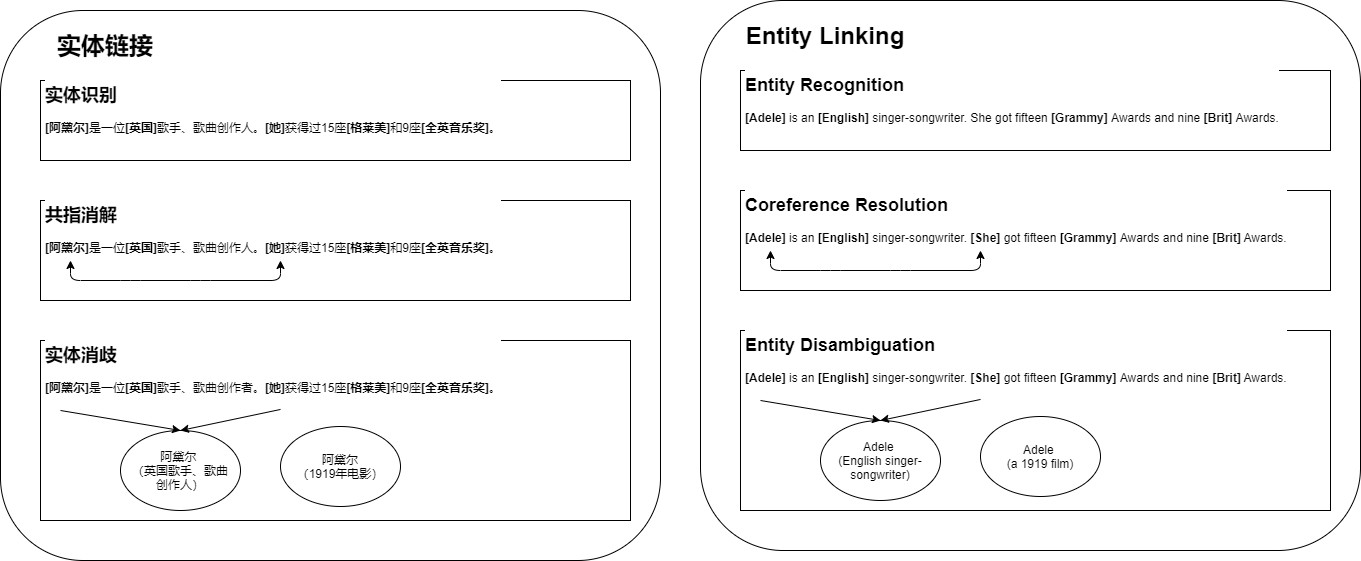
对于构建知识图谱来说,实体链接、实体识别、共指消解、实体消歧几个概念之间的关系应该如下图所示。
方法#
共指消解的难点主要在于:
共指消解已被证明是一个 NP-Hard 问题, 无法在多项式时间内求得最优解
自然语言的场景和句式千变万化,不同的话语可能表述了相同的语义,而相同的话语在不同的语境下表达的含义也可能不同,因此很难构建完整的语言学系统将共指消解的所有情况都考虑周全
Web 语料的质量较低, 大多数语料均为非结构化文本,且数据不一致和缺失的情况时有发生,这大大影响了共指消解模型的性能
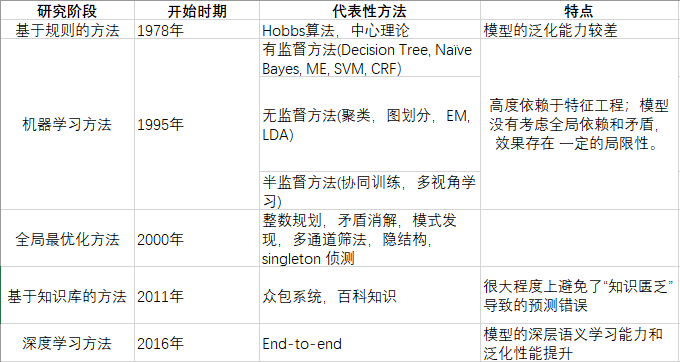
当前,主要的方法如下图所示:
- Mention pair
把共指消解问题看作表述对的二分类问题。从左到右遍历句子,每找到一个指代词,就把它和前面找到的每个先行词作为一个 pair,分类器根据表述对的上下文特征以及距离特征,判断是否共指。
然而这类模型(1)只关注先行词和指代词之间的关系,却忽略了先行词两两之间的相互关系;(2)表述对的特征有时候不足以判断是否共指,可能存在代词语义过空、表述性别难以分辨等种种情况。
- Mention Ranking
把共指消解问题看作排序学习问题。对于一个指代词,和前面所有 k 个先行词按照共指可能进行打分,用 softmax归一化,找出概率最大的先行词。
- Entity Mention
将共指消解问题看作实体与表述的二元分类问题。这里的实体就是共指的先行词集合,由于一个实体包含多个共指先行词, 它们的上下文特征信息能够互补,因此弥补了 Mention pair 模型的第二个缺陷。
- Entity Ranking
结合了 Entity Mention 和 Mention Ranking 模型。给定一个指代词,首先按照共指关系对先行词集合进行划分,转换为实体集合,然后对这些实体和指代词的共指可能性进行打分排序。
前面的讨论都是基于任意两个指代是 coreference 的概率已经计算好了的前提下,那么如何计算这个共指概率?
- Non-neural statistical classifier
特征工程(包括人称、性别一致性等),语义相容性。
- Neural Coref Model
词向量加其他特征。
- End-to-end Model
SOTA, 融合指代识别和指代消解在一个模型里。